前言
在当今AI技术快速发展的时代,文本转语音(TTS)技术已经不再是简单的语音合成,而是能够生成富有表现力、情感丰富的对话音频。对于剧本杀爱好者、内容创作者和教育工作者来说,如何快速创建多角色、高质量的音频内容一直是一个痛点。
传统的TTS工具往往只能处理单一说话人,缺乏角色区分和情感表达,而专业的音频制作又需要大量时间和成本。VibeVoice的出现完美解决了这些问题,它支持最多4个不同说话人,能够生成长达90分钟的对话音频,特别适合制作剧本杀、播客、有声书等内容。
本文将详细介绍如何借助 cpolar 内网穿透,结合 VibeVoice 搭建可随时随地访问的多角色音频生成平台,并以 4 角色对话实战演示,突破传统 TTS 在多说话人场景下的限制。
1 项目概述
1.1 什么是VibeVoice
VibeVoice 是微软开发的一款先进文本转语音(TTS)模型,专注于长对话场景的高质量语音生成。它的核心特点包括:支持多达 4 个不同角色,每个角色拥有独特声音;能够生成长时间连续对话(1.5B 模型可生成约 90 分钟,Large 模型约 45 分钟);具备丰富的情感表达能力,可根据文本自动调整语调与情感色彩;支持中英文语音生成,并具备跨语言迁移能力;同时支持实时流式音频输出,提升互动体验。VibeVoice 适用于多角色剧本、长篇故事朗读以及虚拟助手等场景。
1.2 什么是ComfyUI
ComfyUI 是一个基于节点的可视化界面工具,主要用于构建和管理深度学习模型的推理流程。它通过拖拽式节点连接,将模型加载、数据处理、图像生成等环节直观地呈现出来,使用户无需编写大量代码即可搭建复杂的 AI 流程。ComfyUI 支持多种扩展节点和自定义功能,可以灵活集成第三方模型和插件,同时提供实时预览和调试功能,极大降低了深度学习模型操作的门槛,适合研究者、创作者以及开发者进行快速原型设计和实验。
2 环境安装
重要提示:确保您的系统满足以下要求,否则可能导致安装失败或运行异常。
| 环境项 | 要求说明 |
|---|---|
| 操作系统 | Windows 10/11(推荐) |
| Python版本 | 3.11 |
| 内存 | 至少 8GB RAM,推荐 16GB 以上 |
| 存储空间 | 至少 20GB 可用空间(模型文件较大) |
| 网络环境 | 稳定的网络连接,用于下载模型和依赖 |
| 显卡要求 | NVIDIA GPU,建议 8GB 显存及以上(RTX 20 系列及以上) |
| 显卡驱动 | NVIDIA 驱动 531 及以上(示例环境:580.97) |
| CUDA版本 | CUDA 12(需与 PyTorch/FlashAttention 版本对应) |
| PyTorch版本 | 2.8.0(已编译支持 cu128,即 CUDA 12.8,对应 wheel 包:torch2.8+cu128) |
资料打包下载(含 FlashAttention 2.7.4、VibeVoice 模型(1.5B)、参考音频)
百度网盘:https://pan.baidu.com/s/1IxFfB0SKPiQuIIbiZfKwBQ?pwd=7au3(提取码:7au3)
2.1 安装FlashAttention2
FlashAttention(flash_attn) 是一种针对 Transformer 模型中注意力机制 (Attention) 的高效实现,它的主要作用是 让大模型推理和训练更快、更省显存。
官方GitHub发布页地址:https://github.com/mjun0812/flash-attention-prebuild-wheels/releases
本教程演示安装的FlashAttention版本为2.7.4
在选择Flash-Attention时,需要查看您的显卡驱动支持的CUDA版本信息,在CMD中输入:
nvidia-smi
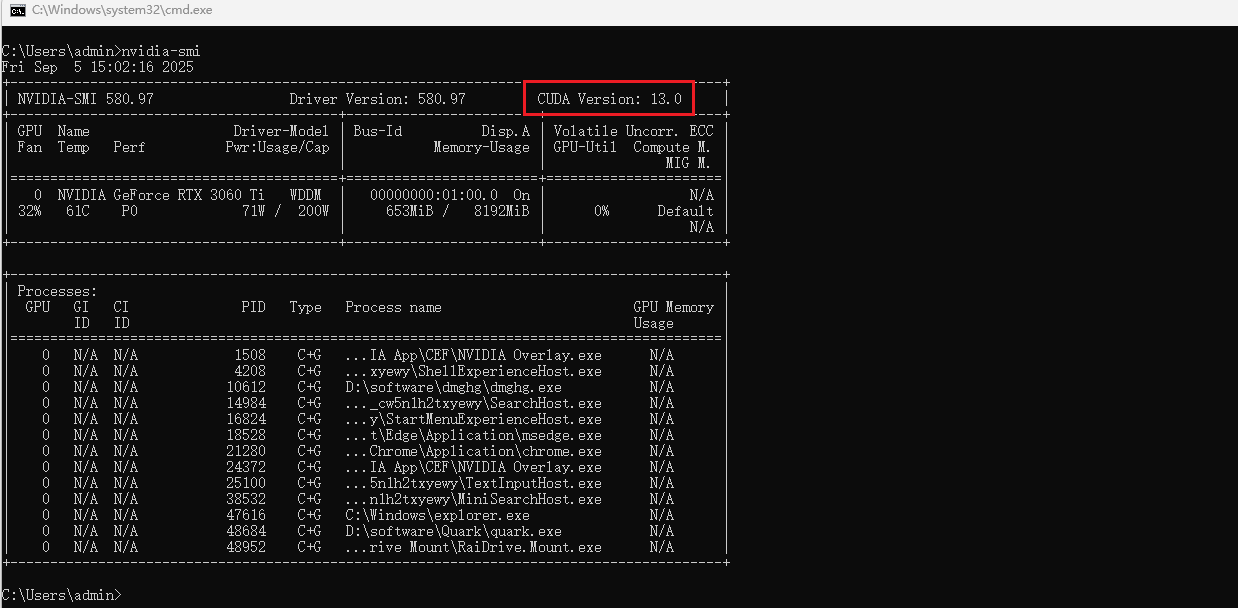
可以看到,当前CUDA版本显示13.0(支持向下兼容一些的)
在发布页下,下载对应你系统环境的whl包:
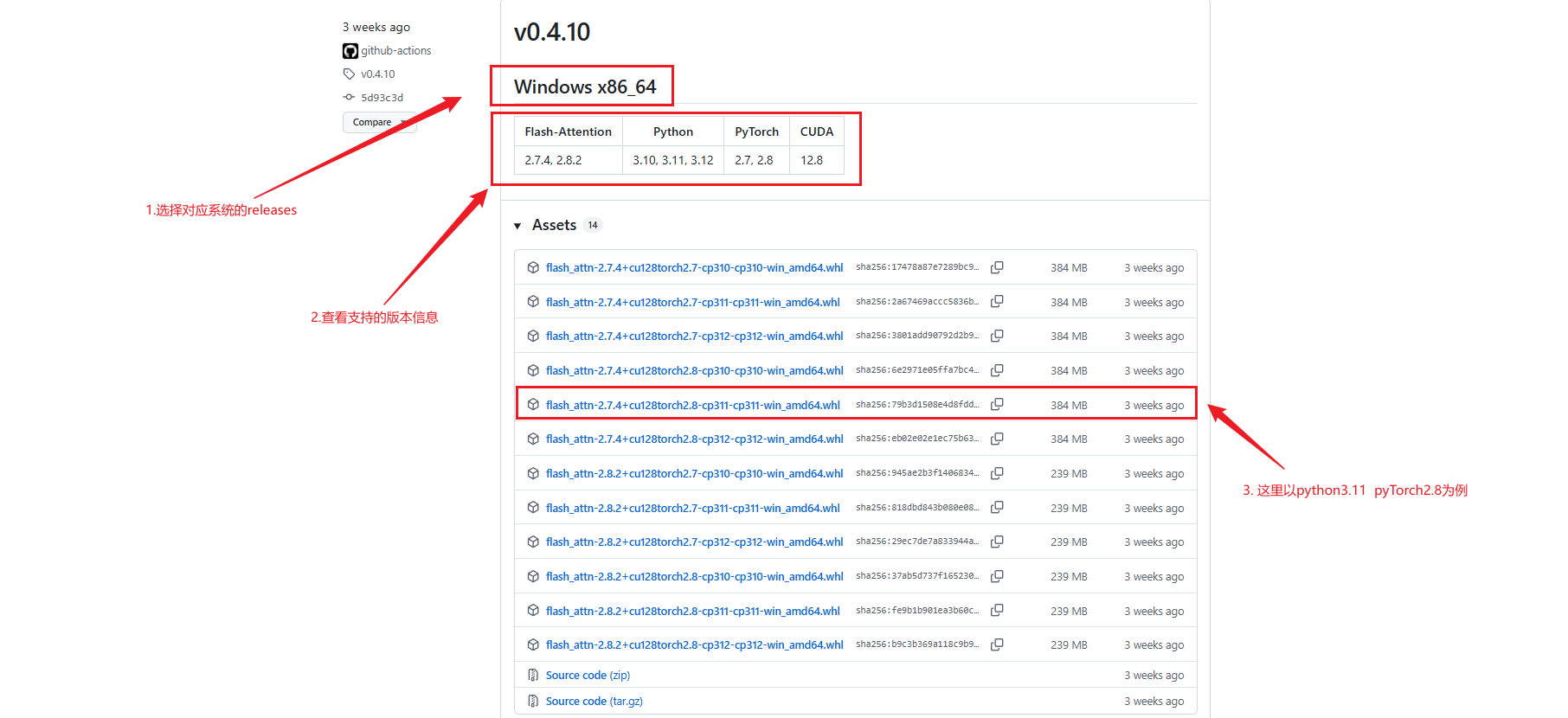
将文件下载至本地:
flash_attn-2.7.4+cu128torch2.8-cp311-cp311-win_amd64.whl
环境要求解析:
cp311-cp311→ 说明需要 Python 3.11torch2.8→ 说明需要 PyTorch 2.8.0cu128→ 说明需要 CUDA 12.8(PyTorch 要用对应的 CUDA 编译版本)win_amd64→ 说明需要 Windows 64 位系统
首先,需要检查当前电脑的python环境,在cmd中输入如下命令检查:
python --version

可以看到已经是python 3.11.4的版本。
如果没有安装python,可前往官网进行安装:https://www.python.org/downloads/
接下来需要检查 PyTorch 版本,同样打开cmd执行:
#1.输入python回车
python
#2.然后输入如下命令
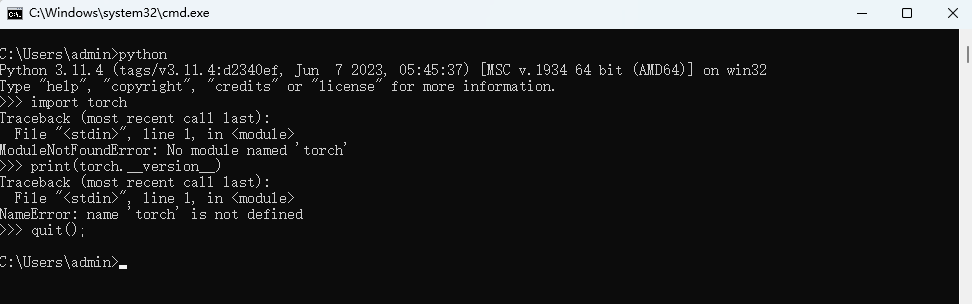
import torch
print(torch.__version__)
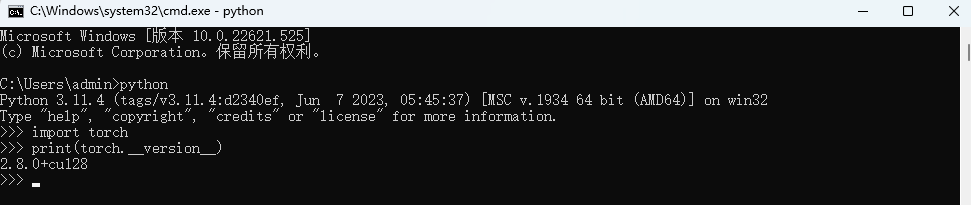
如果没有安装 PyTorch ,显示应如下:
需要执行如下命令进行安装即可:
pip install torch==2.8.0+cu128 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
接下来需要安装FlashAttention2.7.4,在前面已经下载的适配环境的 wheel 文件目录下打开CMD:
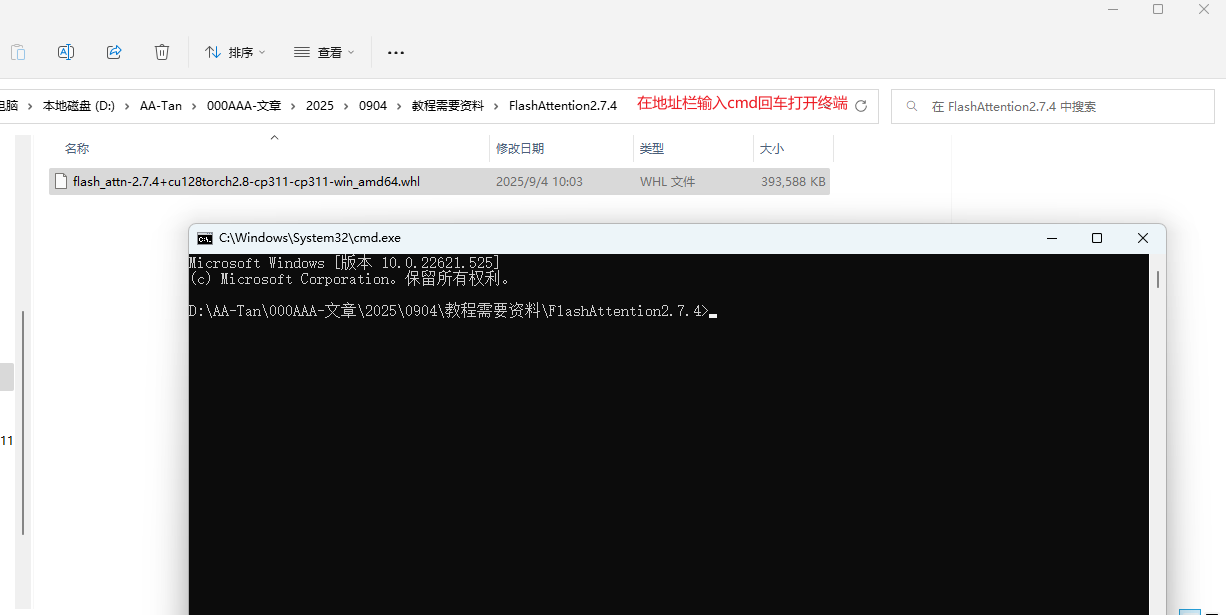
然后输入如下命令进行安装:
pip install flash_attn-2.7.4+cu128torch2.8-cp311-cp311-win_amd64.whl
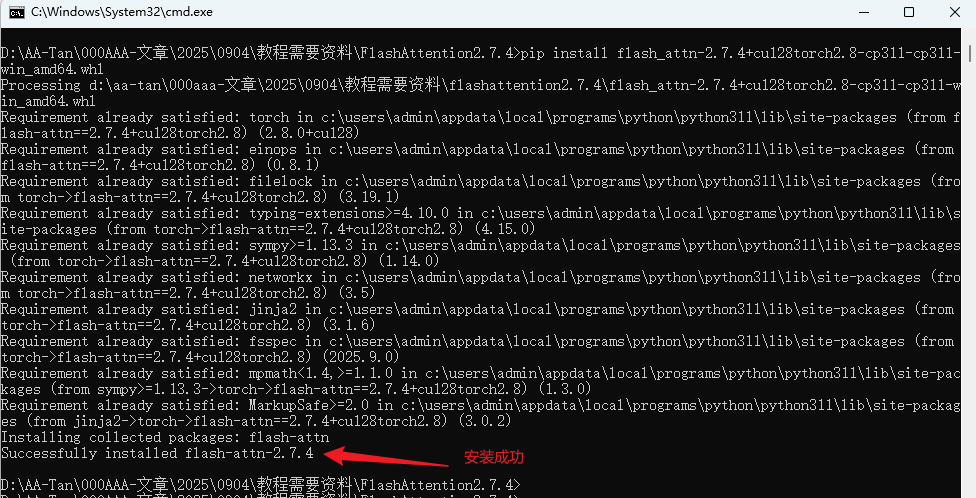
检查版本信息确认安装:
python
import flash_attn
print(flash_attn.__version__)
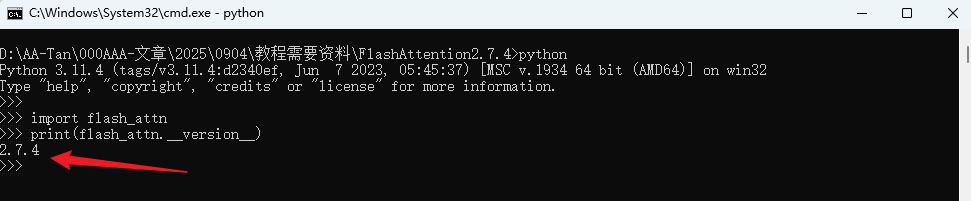
成功安装!
3 ComfyUI工作流项目安装部署
官方GitHub仓库地址:https://github.com/comfyanonymous/ComfyUI
以windows为例,首先使用git命令将项目克隆至本地,cmd执行命令:
git官网地址:https://git-scm.com/downloads
git clone https://github.com/comfyanonymous/ComfyUI.git
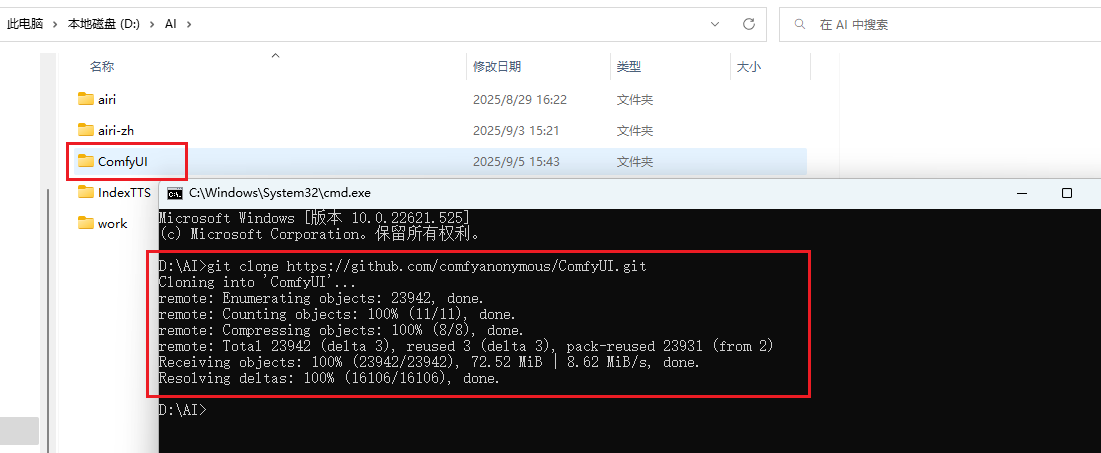
接着继续在该窗口,依次执行如下命令,安装所需依赖:
cd ComfyUI
pip install -r requirements.txt
安装完成依赖后,执行如下命令进行启动测试:
python main.py --listen 0.0.0.0 --port 18188
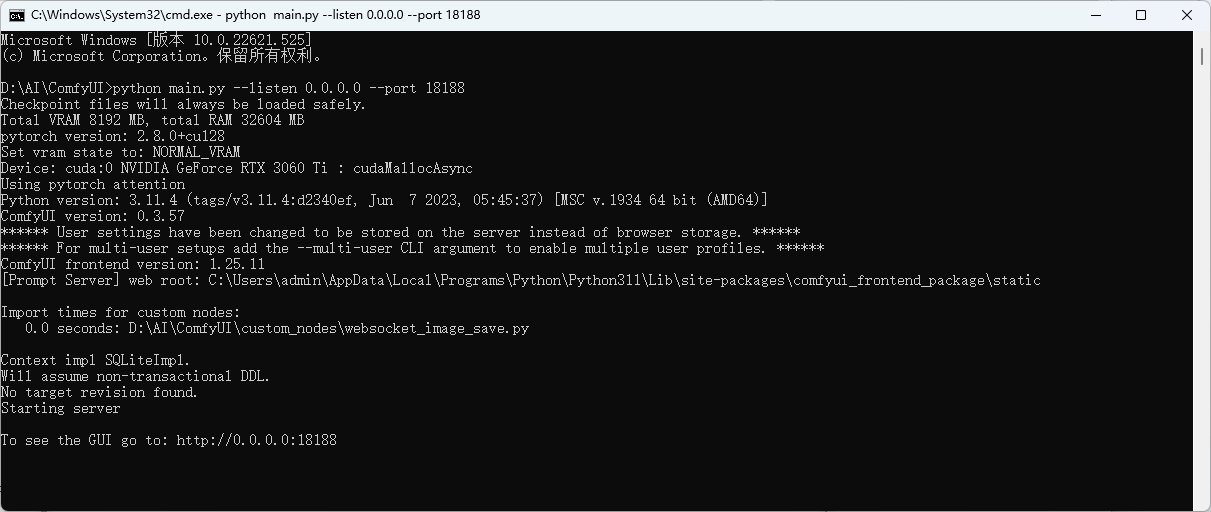 可以看到,成功启动了,端口为 18188,为了后续方便启动,可以写一个bat脚本,将命令放入其中:
可以看到,成功启动了,端口为 18188,为了后续方便启动,可以写一个bat脚本,将命令放入其中:
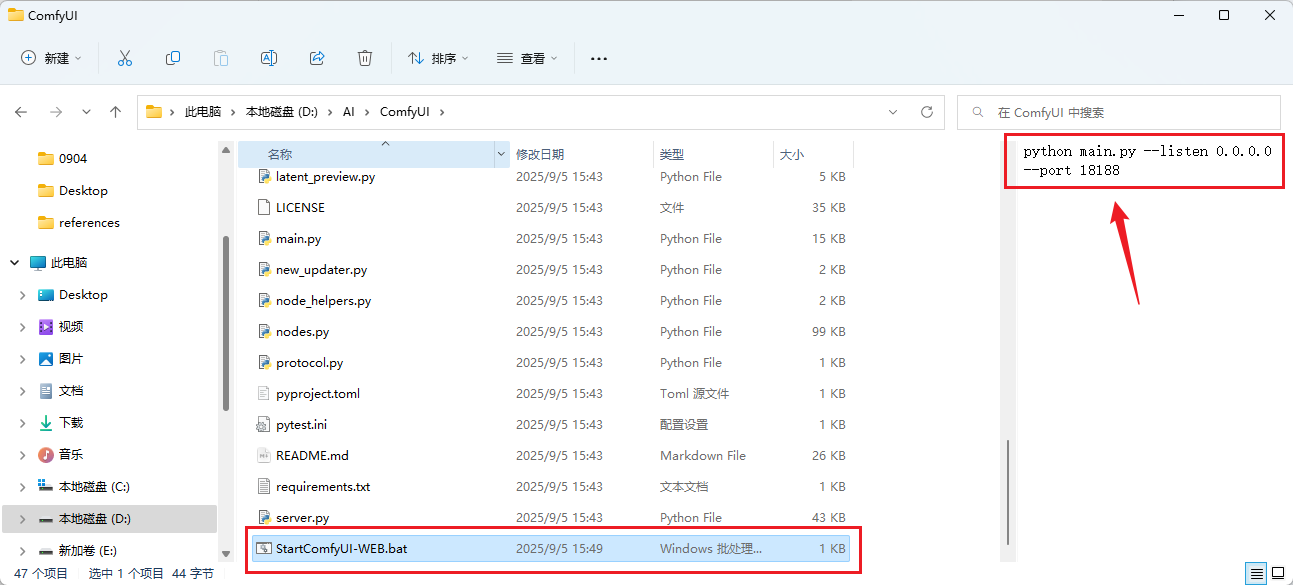
后续双击脚本,就可以直接启动:
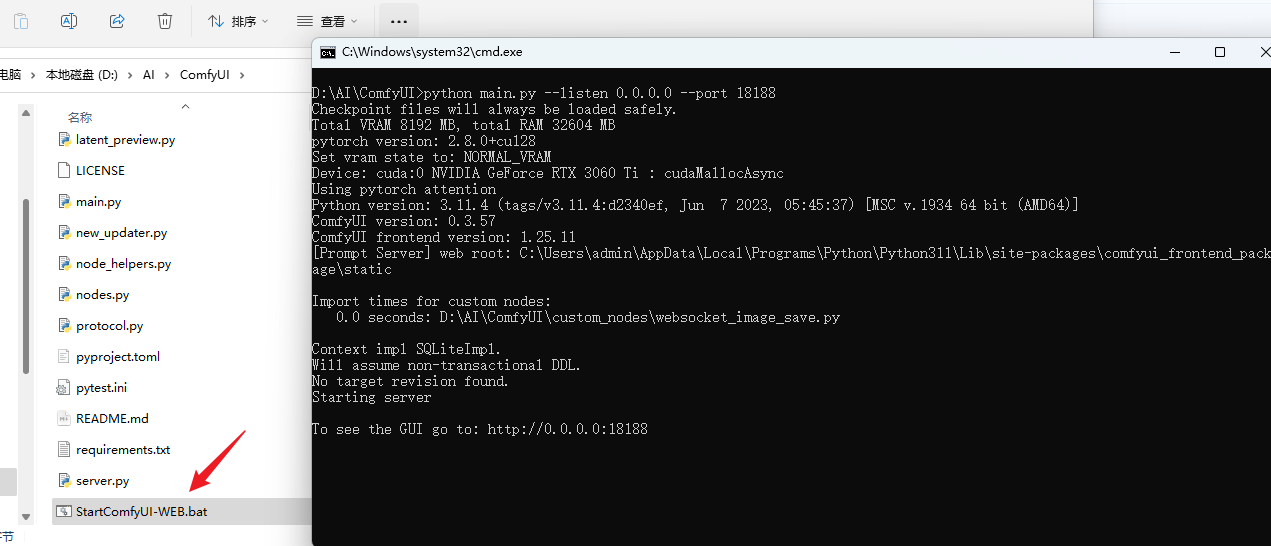
可以看到输出了如下信息:
To see the GUI go to: http://0.0.0.0:18188
让我们访问浏览器进行测试:
#上面显示的0.0.0.0 通常表示绑定到本机的所有网络接口,因此它可以通过本机的任何有效IP地址(包括localhost或127.0.0.1)来访问。
http://localhost:18188
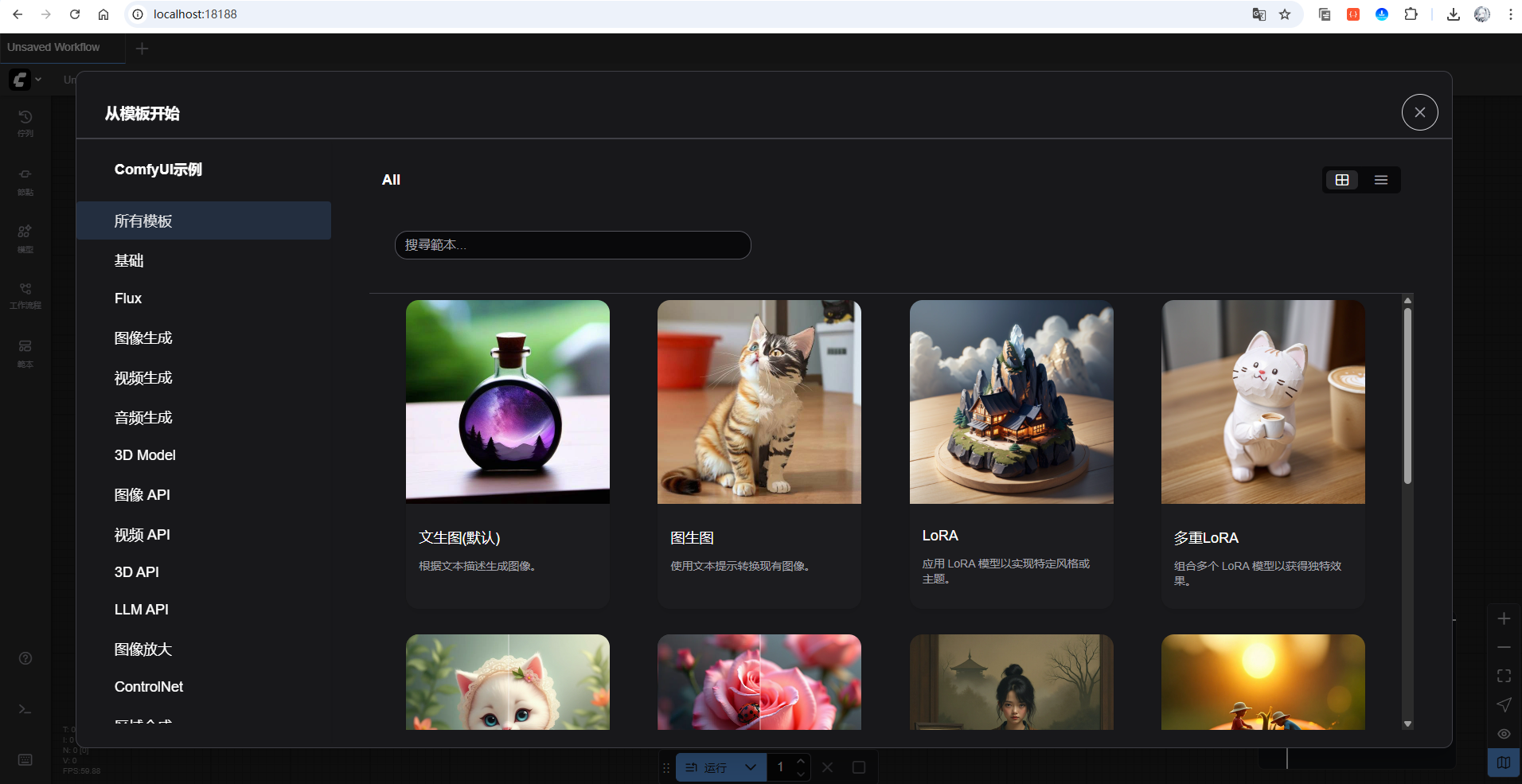
可以看到,成功访问啦!
4 ComfyUI-VibeVoice项目部署
ComfyUI-VibeVoice 是一个为 ComfyUI 开发的自定义插件,它集成了微软的 VibeVoice 文本转语音(TTS)模型,能够实现高质量、多说话人的语音合成与零样本语音克隆。用户只需输入文本并提供参考音频,就可以快速生成风格一致、自然流畅的语音;同时支持多角色对话、长篇内容生成,并提供多种注意力机制和 4-bit 量化以优化性能,适合在播客制作、对话配音、AI 语音实验等场景中使用。
4.1 克隆项目代码
在前面的步骤,已经部署好了ComfyUI工作流项目。接下来需要打开如下目录:
#前面项目clone下来的位置
D:\AI\ComfyUI\custom_nodes
在该目录下打开命令终端,使用git命令将项目克隆下来:
git clone https://github.com/wildminder/ComfyUI-VibeVoice.git
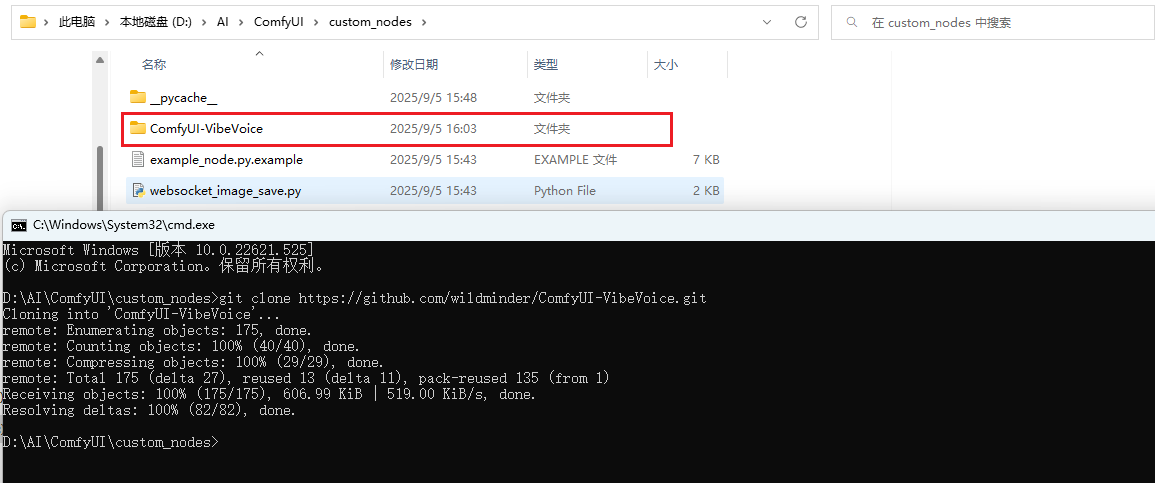
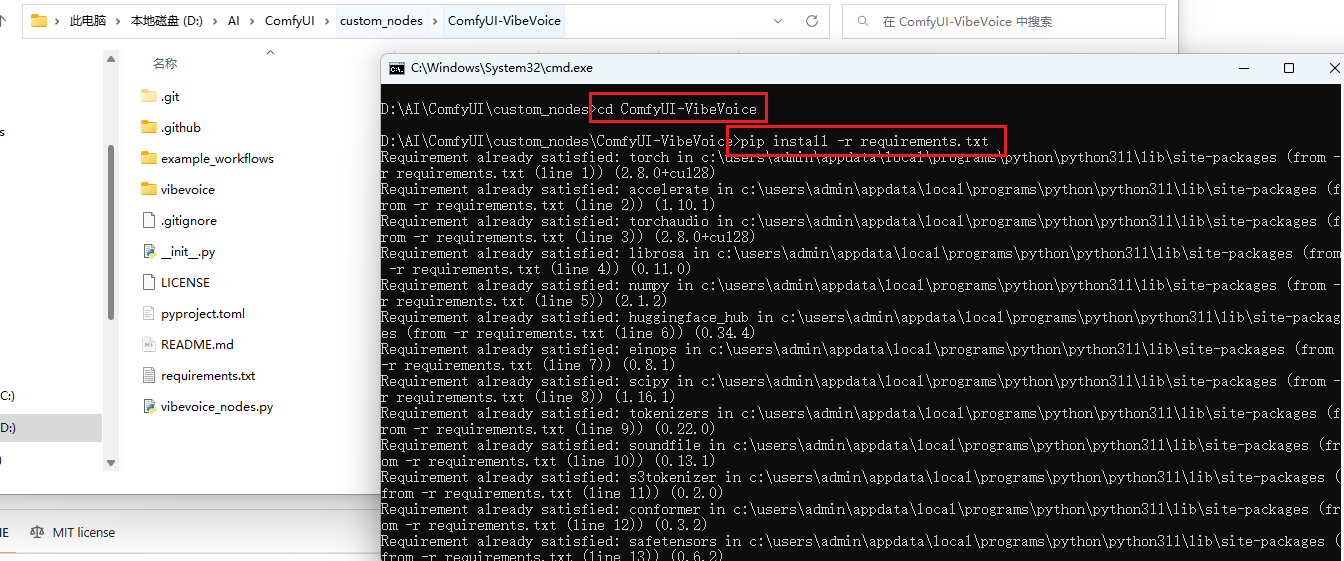
然后接着执行如下命令,下载该项目相关依赖:
cd ComfyUI-VibeVoice
pip install -r requirements.txt
5 ComfyUI 中配置和使用 VibeVoice(实战)
双击启动前面在ComfyUI目录中创建的StartComfyUI-WEB.bat脚本(如果前面启动了,没有停止窗口需要先停止启动的窗口):
启动后在浏览器中访问ComfyUI项目,然后依次如下图选择(或直接按快捷键 Ctrl + O):

接着,进入到如下目录选择VibeVoice_example.json文件,然后点击打开:
D:\AI\ComfyUI\custom_nodes\ComfyUI-VibeVoice\example_workflows
打开后,可以看到如下图显示:
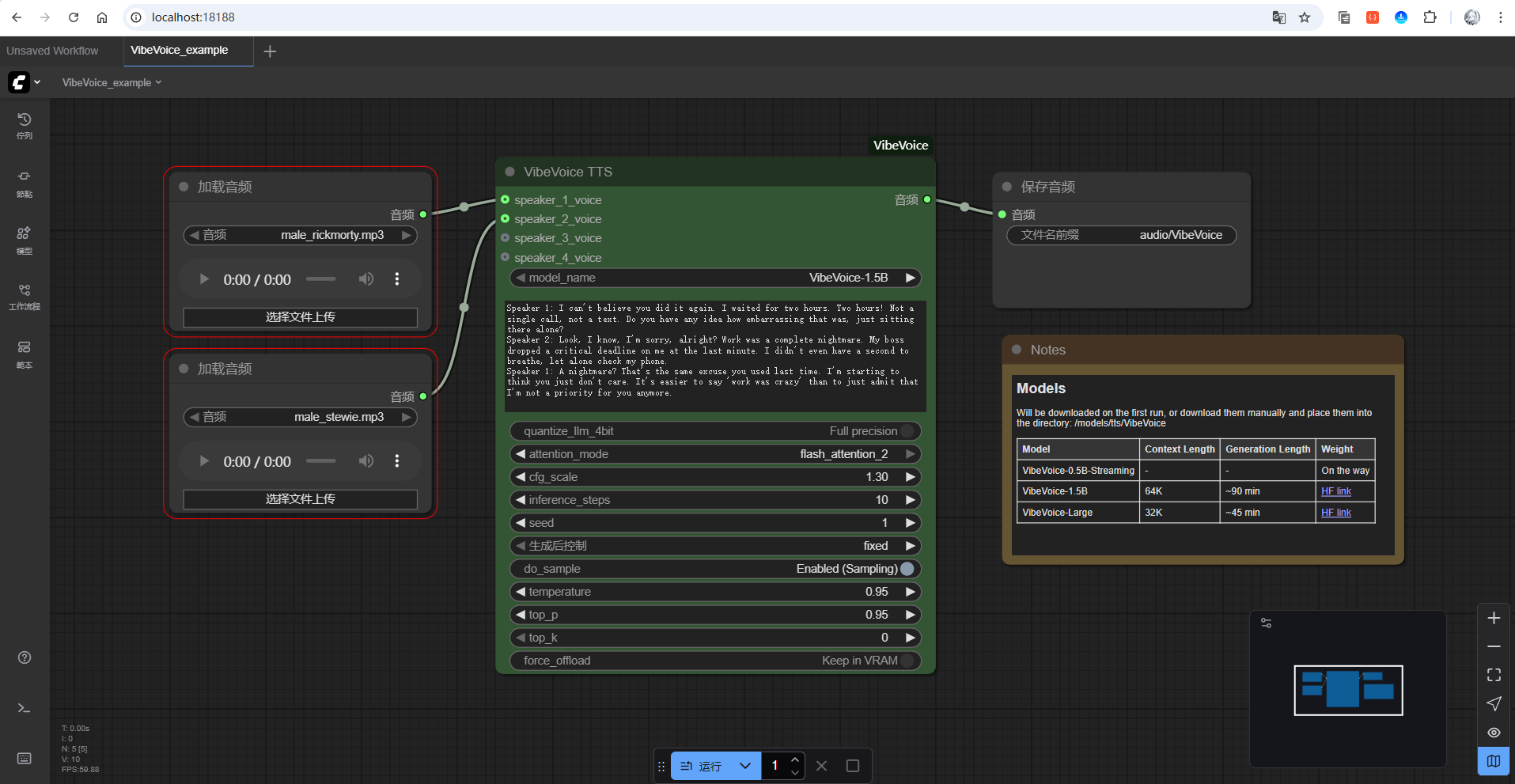
接着,随意上传两个参考音频,然后给定一段对话(这里使用的是AI生成的杨幂和海绵宝宝的对话):
Speaker 1: 哈哈,海绵宝宝,听说你在水下的生活非常有趣,能和我们分享一下吗?
Speaker 2: 哇哦,杨幂!当然可以!我每天都在比奇堡和我的朋友们一起玩,最喜欢的就是和派大星一起做冒险了!
Speaker 1: 这听起来真的很有趣!那你觉得派大星最搞笑的地方是什么?
Speaker 2: 哇,派大星真的很搞笑!他总是那么天真无邪,做事常常没有任何计划,总是带给我们惊喜和笑声!
Speaker 1: 哈哈,感觉你们的冒险一定很欢乐。我想知道,海绵宝宝,你有做过什么特别的事情吗?
Speaker 2: 当然!我曾经当过餐厅经理,在蟹堡王工作,每天都忙得不亦乐乎。不过最特别的还是我做的蟹堡,大家都说我做的最美味!
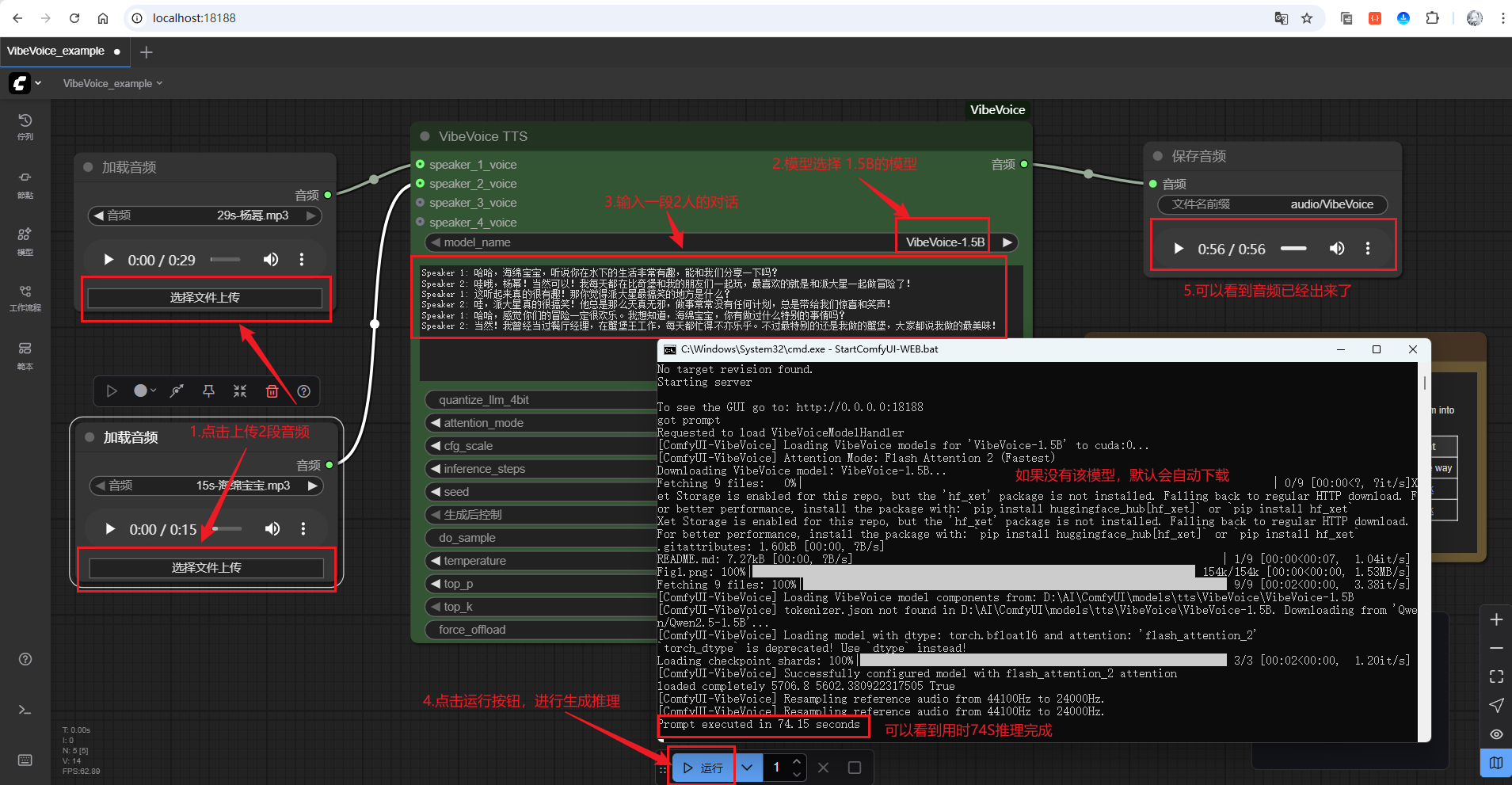
模型选择,首次如果没有该模型会自动进行下载,也可以直接手动下载模型
放入如下文件夹:D:\AI\ComfyUI\models\tts\VibeVoice

完成本地流程配置后,我们将通过 cpolar 将该工作流对外发布,便于跨设备访问与共享。
如下为1.5B模型生成,点击可进行试听:
以下为7B模型开启量化功能后生成推理的语音(3060ti的8G显存无法完全加载7B模型):
6 使用 cpolar 将 ComfyUI 安全暴露到公网
6.1 为什么要穿透comfyUI
借助 cpolar 内网穿透,我们无需公网 IP 与路由配置,即可将本地 ComfyUI 服务稳定、安全地发布到公网,支持 HTTPS 与固定二级域名。
很多时候我们在本地电脑或者服务器上部署了 ComfyUI,但又希望能随时从其他设备访问,比如远程调试、和同事协作修改节点,或者在不同地方展示模型生成效果。问题是 ComfyUI 默认只能在本地访问,外网根本无法连接,这就让远程使用变得非常麻烦,需要复杂的路由设置或者固定公网 IP。通过内网穿透工具如 cpolar,我们可以把本地的 ComfyUI 安全地映射到公网,生成一个随时可用的公网地址。这样无论身处何地,都能轻松访问和操作 ComfyUI,实现远程协作和展示,而不必再为网络配置烦恼。
6.2 什么是 cpolar(内网穿透)?
- cpolar 是一款内网穿透工具,可以将你在局域网内运行的服务(如本地 Web 服务器、SSH、远程桌面等)通过一条安全加密的中间隧道映射至公网,让外部设备无需配置路由器即可访问。
- 广泛支持 Windows、macOS、Linux、树莓派、群晖 NAS 等平台,并提供一键安装脚本方便部署。
6.3 下载cpolar
打开cpolar官网的下载页面:https://www.cpolar.com/download
点击立即下载 64-bit按钮,下载cpolar的安装包:
下载下来是一个压缩包,解压后执行目录中的应用程序,一路默认安装即可,安装完成后,打开cmd窗口输入如下命令确认安装:
cpolar version

出现如上版本即代表安装成功!
安装完成后,cpolar 将作为本方案“公网访问能力”的关键基础,贯穿后续所有远程访问与协作场景。
6.4注册及登录cpolar web ui管理界面
6.4.1 注册cpolar
官网链接:https://www.cpolar.com/
访问cpolar官网,点击免费注册按钮,进行账号注册
注册页面:

6.4.2 访问web ui管理界面
注册完成后,在浏览器中输入如下地址访问 web ui管理界面:
http://127.0.0.1:9200
输入刚才注册好的cpolar账号登录即可进入后台页面:
6.5 使用 cpolar 穿透 ComfyUI 的 WebUI 界面
前面可以看到,comfyUI的WebUI的界面,端口显示为:18188

所以我们需要将该端口进行穿透以支持咱们公网访问!
6.5.1 随机域名方式(免费方案)
使用 cpolar 的随机域名方式适合预算有限的用户。使用此方式时,系统会每隔 24 小时左右 自动更换一次域名地址。对于长期访问的不太友好,但是该方案是免费的,如果您有一定的预算,可以查看大纲6.5.2 的固定域名方式,且访问更稳定。
点击左侧菜单栏的隧道管理,展开进入隧道列表页面,页面下默认会有 2 个隧道:
- ssh隧道,指向22端口,tcp协议
- website隧道,指向8080端口,http协议(http协议默认会生成2个公网地址,一个是http,另一个https,免去配置ssl证书的繁琐步骤)
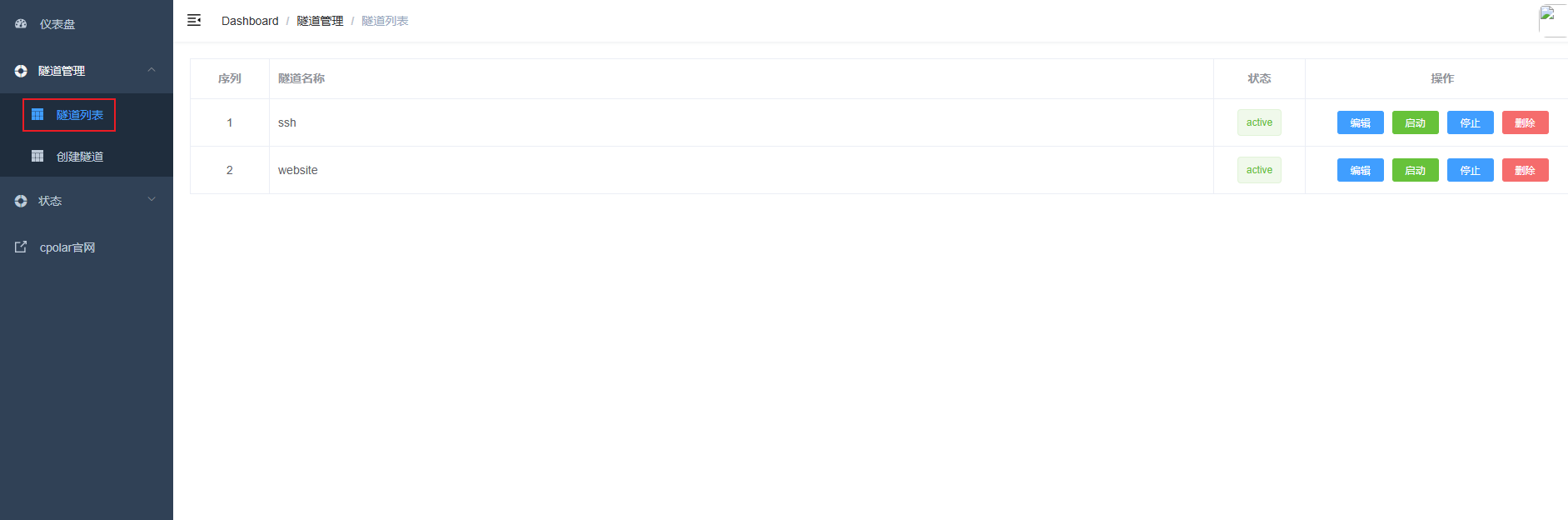
点击website隧道的编辑按钮,填写如下信息:
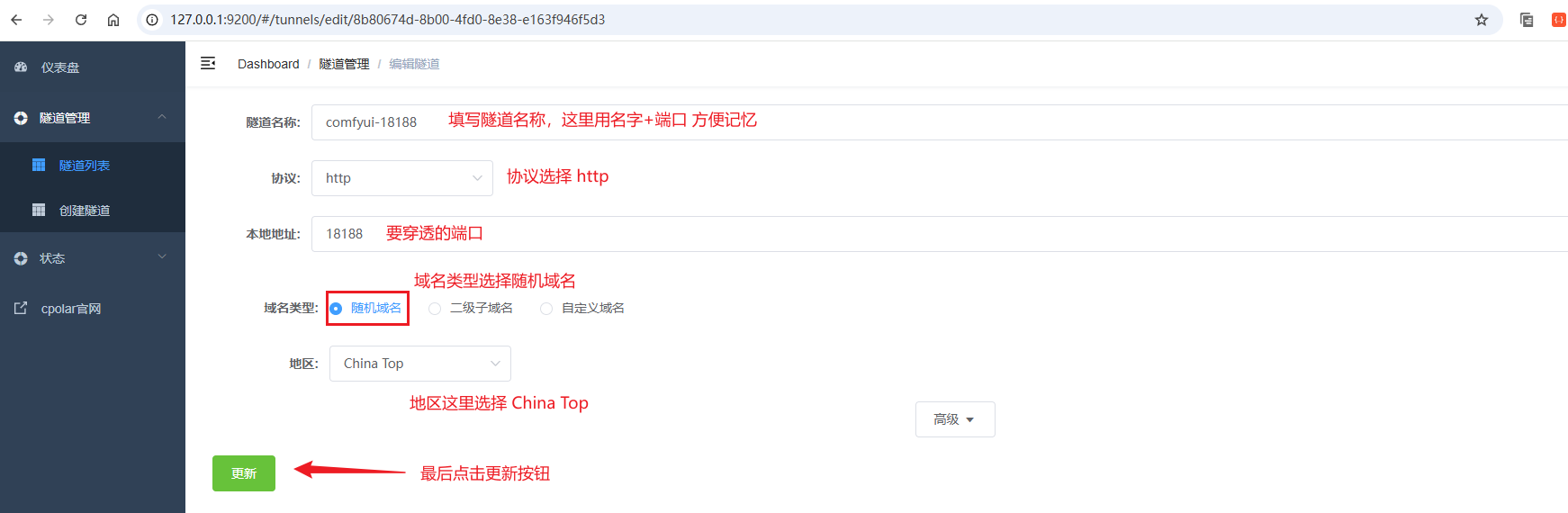
- 注意:每个用户创建的隧道显示的公网地址都不一样!
接着,点击左侧菜单的状态菜单,接着点击在线隧道列表菜单按钮,可以看到有2个comfyui-18188的隧道,一个为 http 协议,另一个为 https 协议:
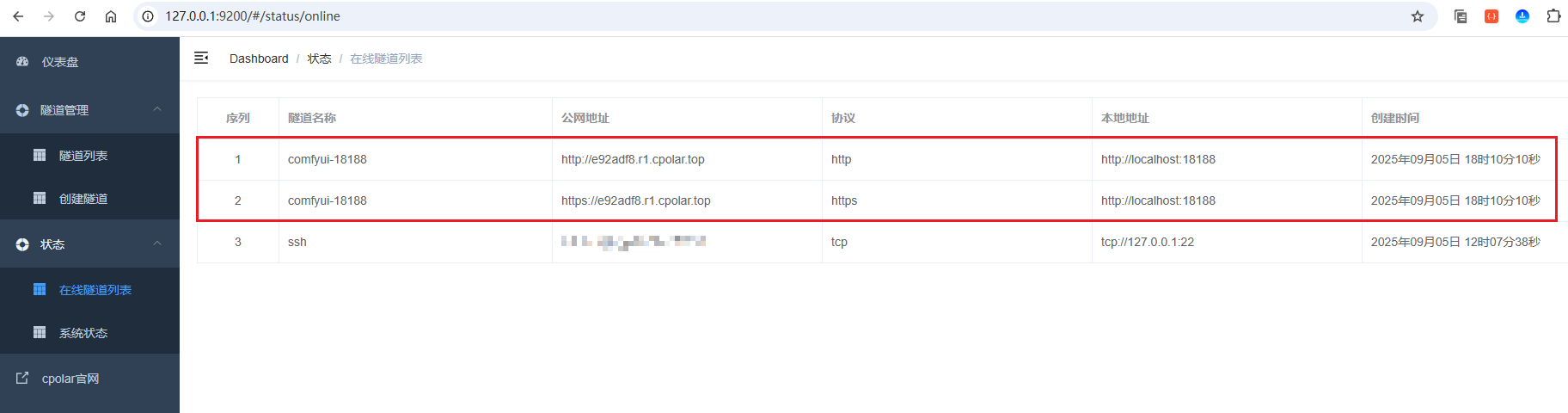
接下来在浏览器中访问 website 隧道生成的公网地址(http 和 https 皆可)
这里以https为例:
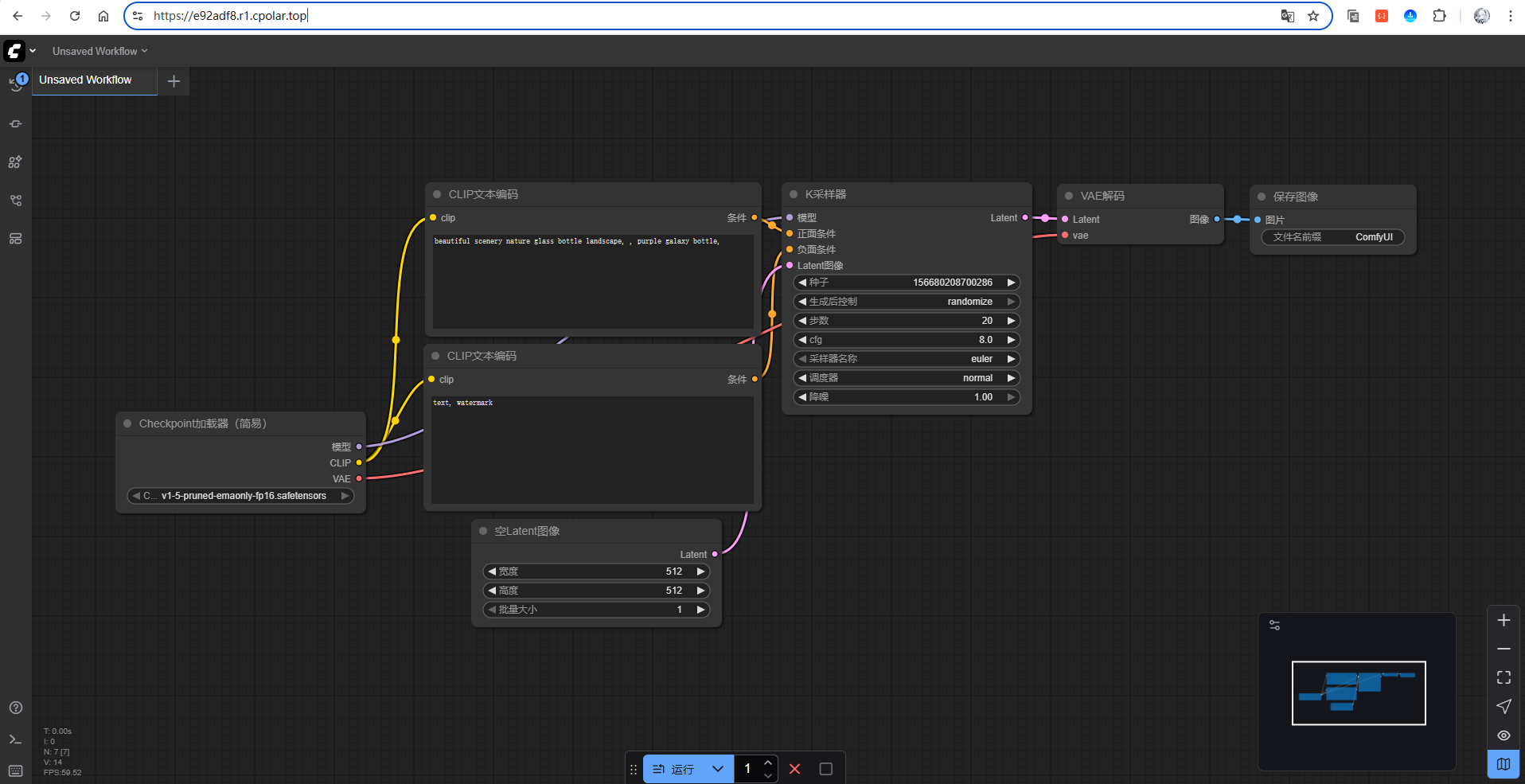
可以看到成功访问啦!
6.5.2 固定域名方式(升级套餐)
通过 cpolar 的固定二级子域名方式(升级套餐),可获得稳定不变的公网地址,便于长期访问与对外分享。
进入官网的预留页面:https://dashboard.cpolar.com/reserved
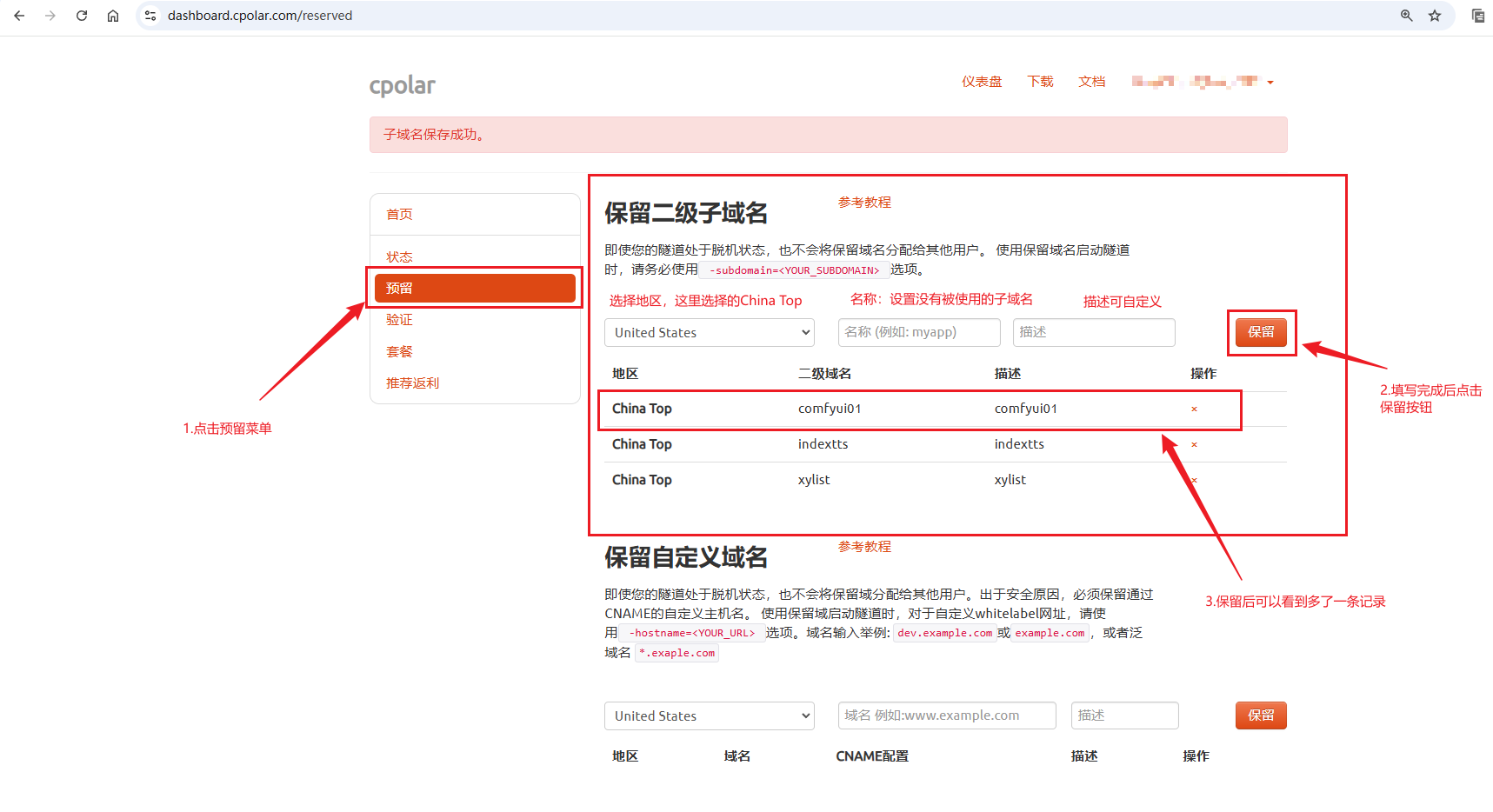
列表中显示了一条已保留的二级子域名记录:
- 地区:显示为
China Top。 - 二级域名:显示为
comfyui01。
注:二级域名是唯一的,每个账号都不相同,请以自己设置的二级域名保留的为主
进入侧边菜单栏的隧道管理下的隧道列表,可以看到名为comfyui-18188的隧道
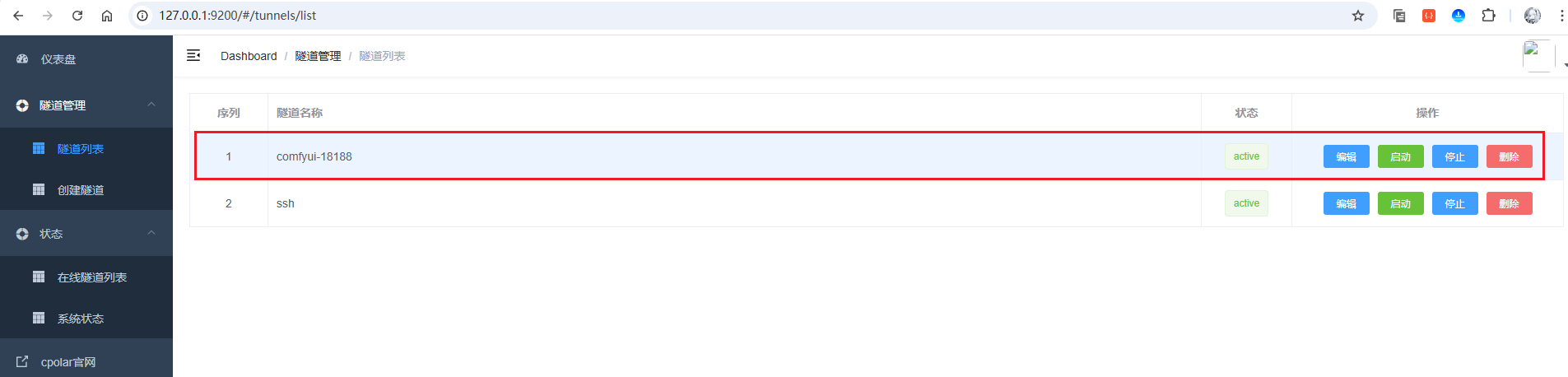
点击编辑按钮进入编辑页面,修改域名类型为二级子域名,然后填写前面配置好的子域名,点击更新按钮:
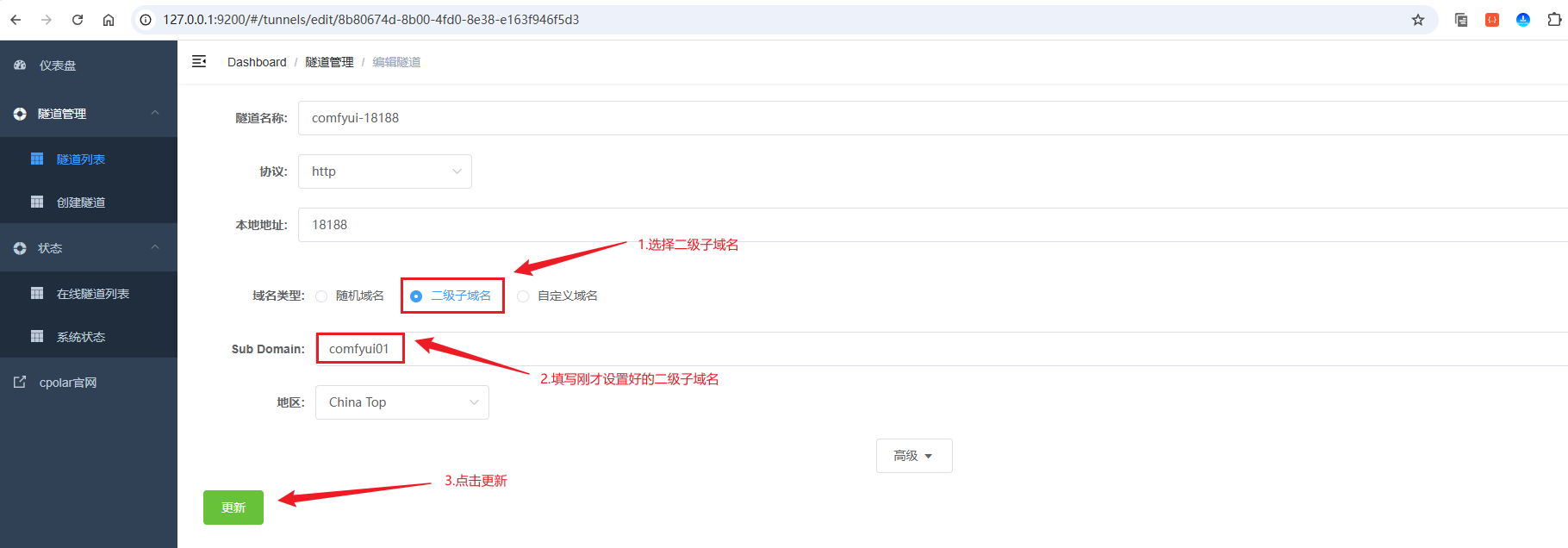
来到状态菜单下的在线隧道列表可以看到隧道名称为comfyui-18188的公网地址已经变更为二级子域名+固定域名主体及后缀的形式了:
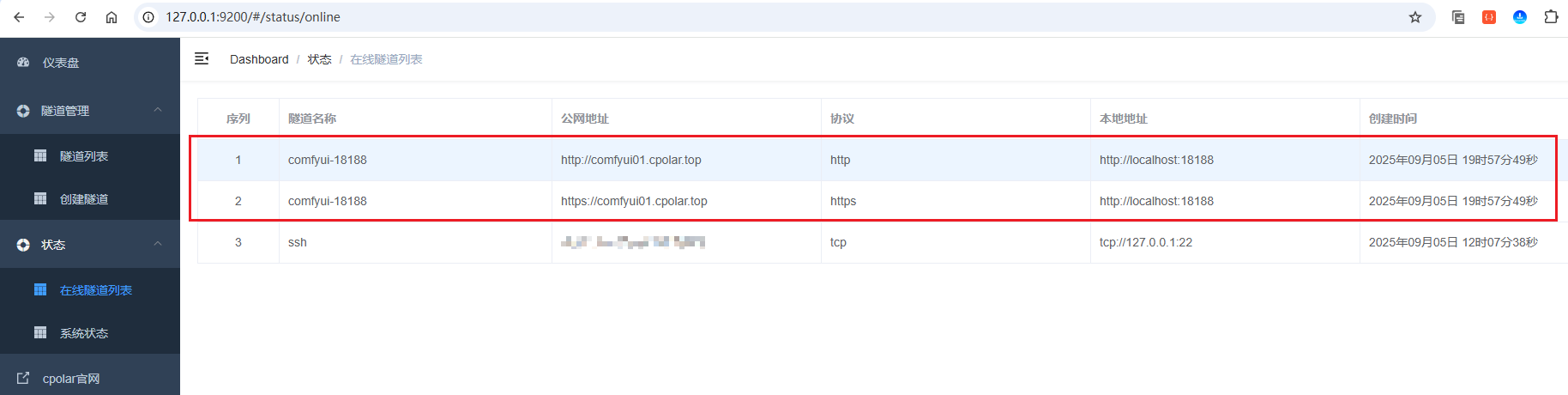
这里以https协议做访问测试:
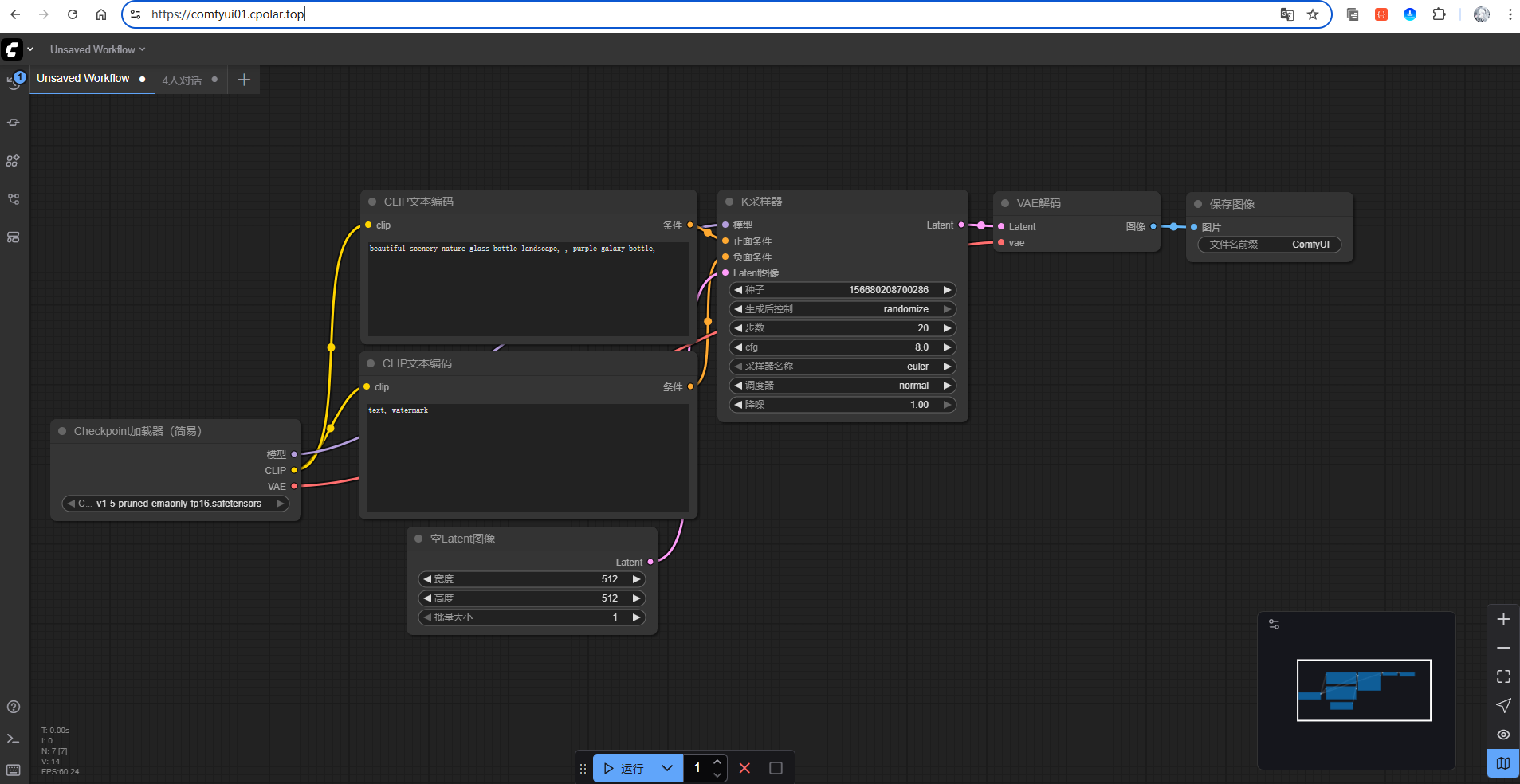
访问成功!
至此,依托 cpolar,我们已将本地 ComfyUI 服务稳定发布到公网,便于团队远程协作与外部演示。
6.6 给ComfyUI添加授权验证
由于ComfyUI服务的WebUI界面无需登录即可进行访问,为了保护个人的隐私即安全,cpolar的隧道服务支持给网站添加授权验证功能,防止您部署在家中的ComfyUI服务被滥用。
首先,打开隧道列表,点击编辑comfyui-18188的隧道:
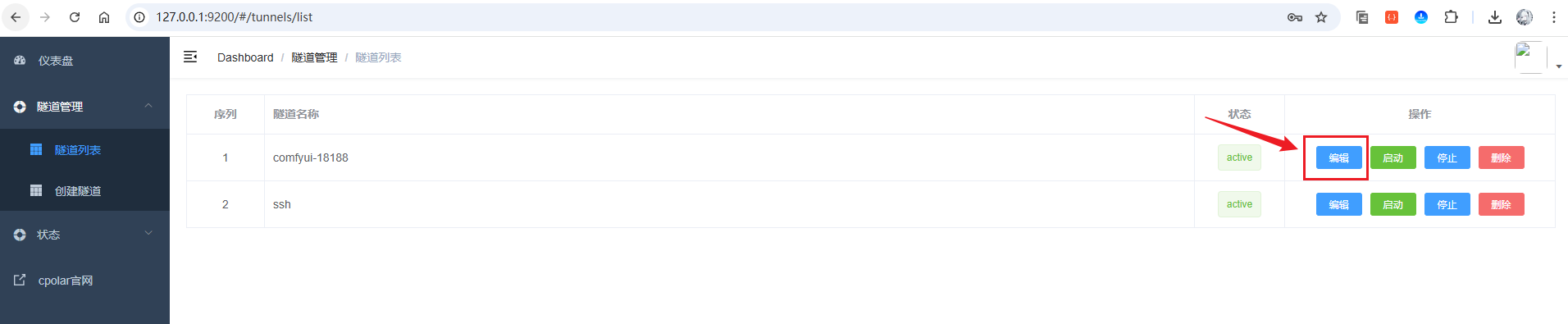
然后,点击高级按钮,展开,按照如下图进行配置:
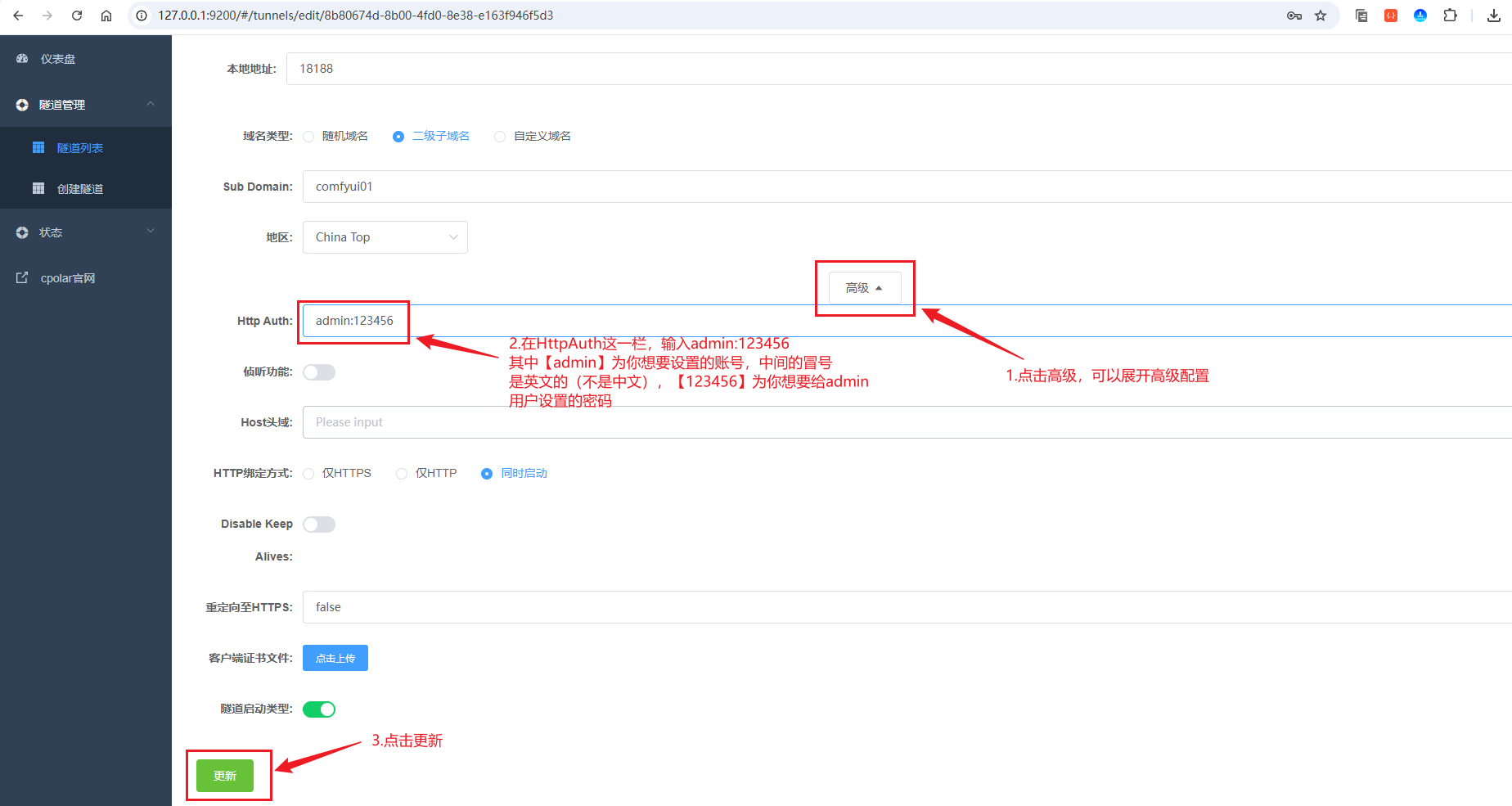
点击更新按钮后,访问穿透的地址,可以发现需要授权验证:
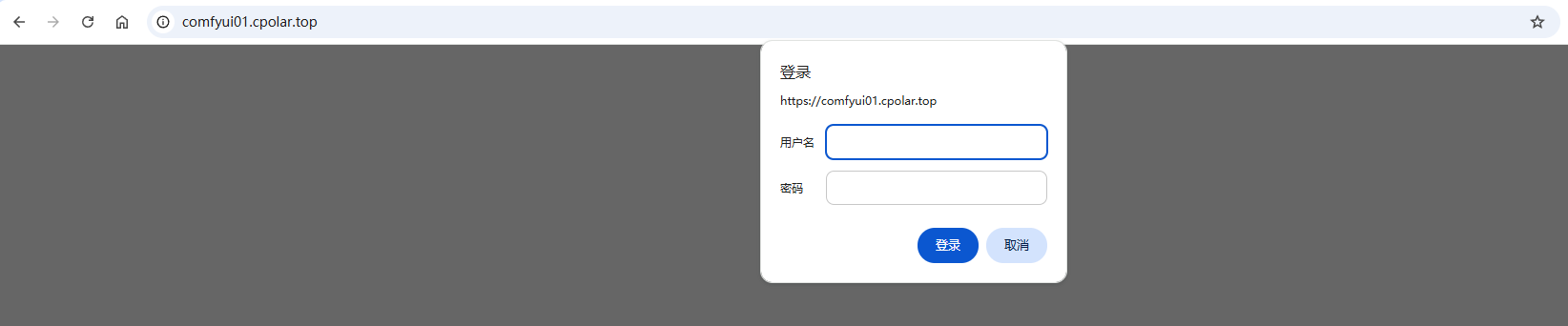
这样,一个可以随时访问且带有安全性的ComfyUI的工作流网页端就弄好啦!
7 三人对话和四人对话测试
7.1 三人对话
首先准备一段对话内容:
Speaker 1: 大家好,好久不见了!我们今天终于可以好好聊聊了。
Speaker 2: 是啊,最近工作太忙了,终于能和大家放松一下了。
Speaker 3: 哈哈,你们有没有发现,我们三个凑在一起,话题根本停不下来。
Speaker 1: 最近我在拍一部古装剧,造型超级复杂,每天都要花三个小时化妆。
Speaker 2: 哇,那也太辛苦了!我最近在做新歌demo,熬夜熬到快失眠了。
Speaker 3: 看来大家都很拼啊,我这边刚从巡演回来,现在只想休息睡觉。
这里的Speaker 1和Speaker 2以及Speaker 3分别对应的参考音频如下:
- Speaker 1:杨幂
- Speaker 2:蔡徐坤
- Speaker 3:王俊凯
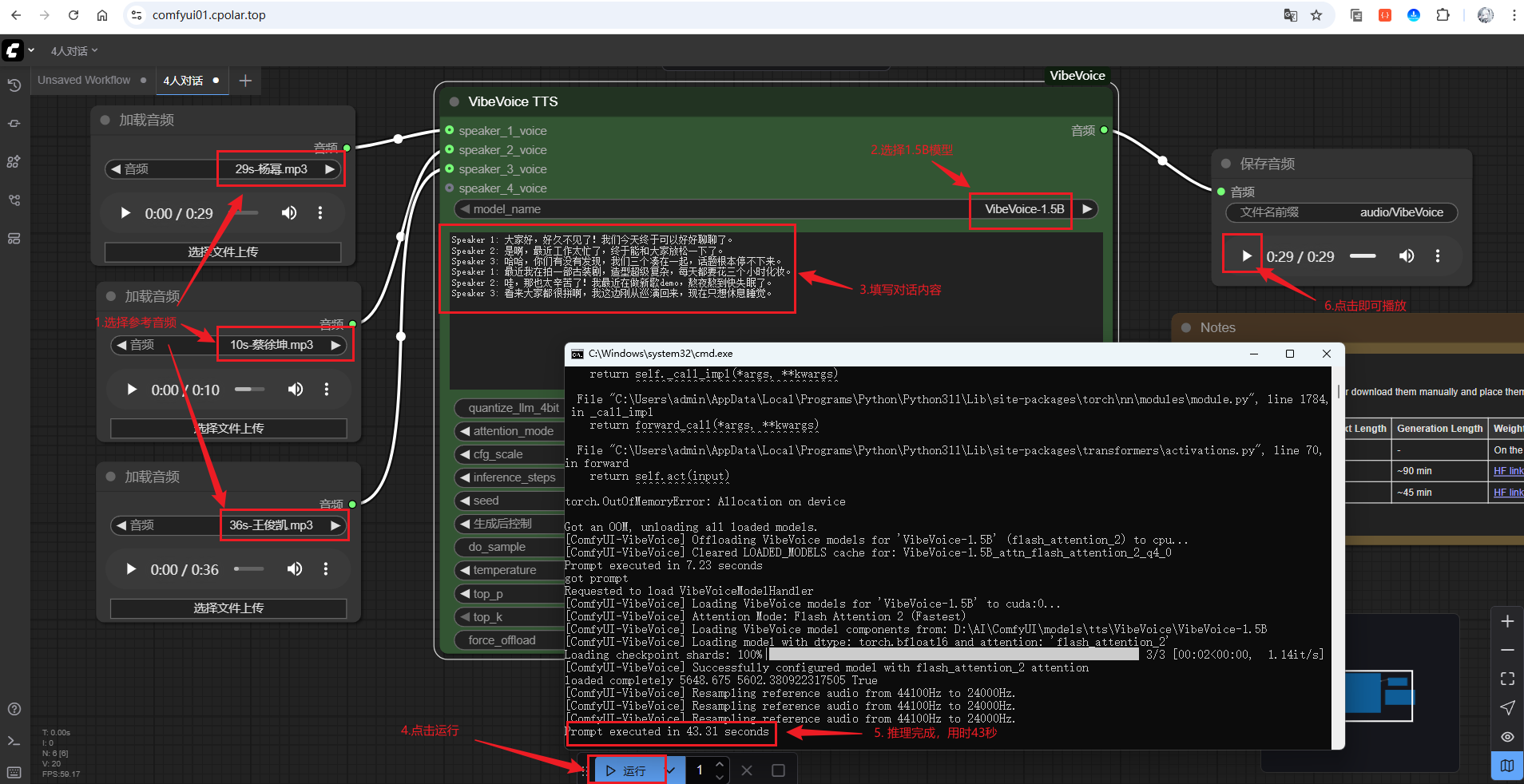
让我们试听一下3人对话的效果:
由于演示的windows系统,3060ti显卡,显存为8G,推理 7B 模型内存会超出,所以这边就不做7B的演示了
7.2 四人对话
在前面的对话内容基础上,添加一个新的角色Speaker 4,这里使用的参考音频为:
- Speaker 4:林志玲
Speaker 1: 大家好,好久不见了!我们今天终于可以好好聊聊了。
Speaker 2: 是啊,最近工作太忙了,终于能和大家放松一下了。
Speaker 3: 哈哈,你们有没有发现,我们四个凑在一起,话题根本停不下来。
Speaker 4: 听到你们的声音我就觉得特别温暖,今天一定要聊个尽兴!
Speaker 1: 最近我在拍一部古装剧,造型超级复杂,每天都要花三个小时化妆。
Speaker 2: 哇,那也太辛苦了!我最近在做新歌demo,熬夜熬到快失眠了。
Speaker 3: 看来大家都很拼啊,我这边刚从巡演回来,现在只想休息睡觉。
Speaker 4: 我和你们比轻松多了,最近主要在做一些公益活动,也蛮充实的。
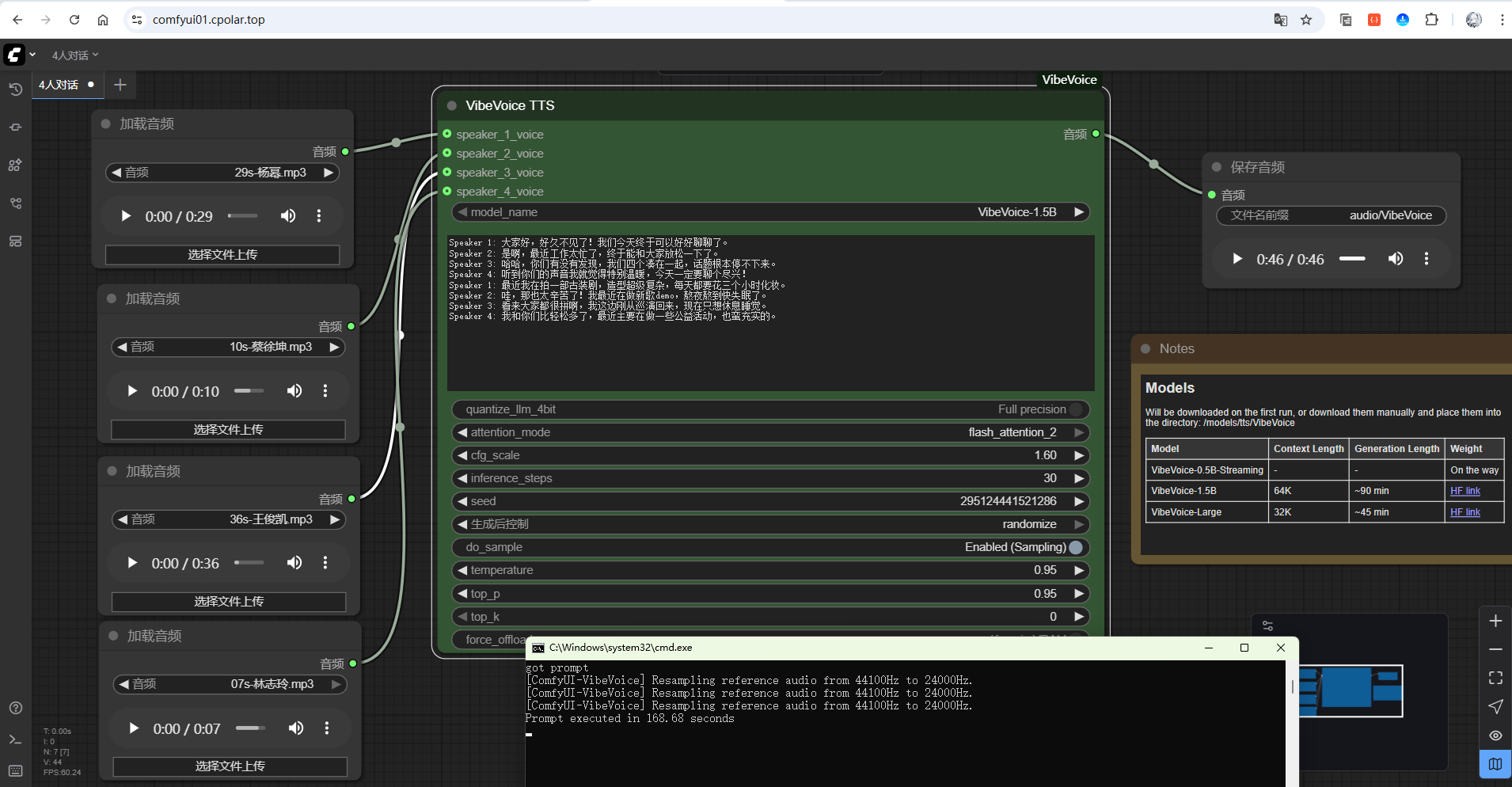
让我们试听一下4人对话的效果:
可以看到,4人对话的效果也是非常不错的,都是演示了2轮对话。推理显示用了 180s 左右,还是很不错的!
总结
借助 cpolar 内网穿透,结合 VibeVoice 与 ComfyUI,本文完整演示了 4 角色对话音频的实战生产流程,有效突破传统 TTS 在多说话人场景下的限制,为内容创作者、教育从业者和剧本杀爱好者提供了强大而实用的工具。
- 多角色支持:VibeVoice 支持最多 4 个不同说话人,每个角色拥有独特的声音特征
- 长对话生成:1.5B 模型可生成约 90 分钟的连续对话,满足长篇内容制作需求
- 情感表达丰富:可根据文本自动调整语调与情感色彩,生成自然流畅的语音
- 可视化操作:ComfyUI 提供直观的节点式界面,无需编程即可完成复杂工作流
- 公网访问:通过 cpolar 内网穿透,实现随时随地访问和协作
这个平台不仅技术先进,而且操作简单,为 AI 音频内容创作开辟了新的可能性。无论是个人创作者还是专业团队,都能从中获得巨大的价值。
依托 cpolar 的 HTTPS 与固定子域名能力,创作流程可被稳定地分享与远程协作,显著提升了 AI 音频生产的传播效率与协同体验。
感谢您阅读本篇文章,有任何问题欢迎留言交流。cpolar官网-安全的内网穿透工具 | 无需公网ip | 远程访问 | 搭建网站





